1x1 픽셀로 시작되는 Velog 조회수 확인 API 개발기

들어가며
이 글은 내부 작동 구조 설명에 초점을 맞춰 작성되었습니다. 설치·배포 방법, 자세한 API Reference, 전체 코드는 Github 저장소에서 확인하실 수 있습니다.
velog-view-counter는 API 요청을 처리하기 위해 Workers API Gateway를 사용합니다. 라우팅 처리 방식과 미들웨어 확장 방법에 대해 궁금하신 분들은 Cloudflare Workers로 Express.js 스타일 API Gateway 프레임워크 만들기 게시글을 참고해주시면 됩니다.
Cloudflare Workers, KV, Wrangler 등 Cloudflare 개발자 플랫폼이 낯설다면 아래 글들을 먼저 참고해 주세요.
- Cloudflare Workers & KV 이용해서 서버리스 방문자 카운팅 API 만들기(1/2): Workers, Workers KV 소개, 사용법 및 배포 방법을 설명합니다
- Cloudflare Workers & KV 이용해서 서버리스 방문자 카운팅 API 만들기(2/2): CORS, 사용자 소유 도메인 적용 및 SSG(Static Site Generation) 빌드 블로그 통합 방법을 설명합니다
개발 배경
블로그 홍보와 검색 유입을 위해 Velog에도 글을 올리다 보니, 게시글별 조회수를 확인하려면 매번 로그인해 게시글 클릭 → 통계 확인을 반복해야 하는 게 너무 번거로웠습니다.
Google Analytics 같은 통계 서비스까진 바라지 않더라도, 최소한 어느 기기에서 언제 게시글 조회했는지 정도는 알고 싶은 마음과, 방문자는 없어도 API는 있는 개발자답게 없으면 내가 만든다는 정신으로 화려한 UI 대신 확장성에 초점을 맞춘 Velog 조회수 확인 API를 직접 만들게 되었습니다.
구현 아이디어
상대방을 알아야 나를 알 수 있듯이, Velog와 브라우저의 작동 방식을 알아야 그에 맞춰 나만의 API를 설계할 수 있습니다.
- Velog는 Markdown 문법을 지원합니다.
- Markdown 문법으로 사용자 소유 도메인에서 호스팅 되는 이미지 파일을 삽입할 수 있습니다.
- 브라우저는 cross-site 도메인이어도 단순 이미지 호출은 차단하지 않습니다.
- 게시글에 1×1 픽셀 투명 이미지를 삽입하면, 페이지가 로드(게시글 조회) 될 때마다 서버가 호출 기록을 남길 수 있습니다.
여기서 핵심은 이미지(투명한 1x1 픽셀)를 자체 도메인에서 호출하는 것입니다. 간혹 다른 플랫폼의 경우에는 사용자 도메인 이미지를 자신들 도메인(CDN)으로 강제 캐싱 하는 경우도 있어서 Velog는 어떻게 작동하는지 확인해 보겠습니다.
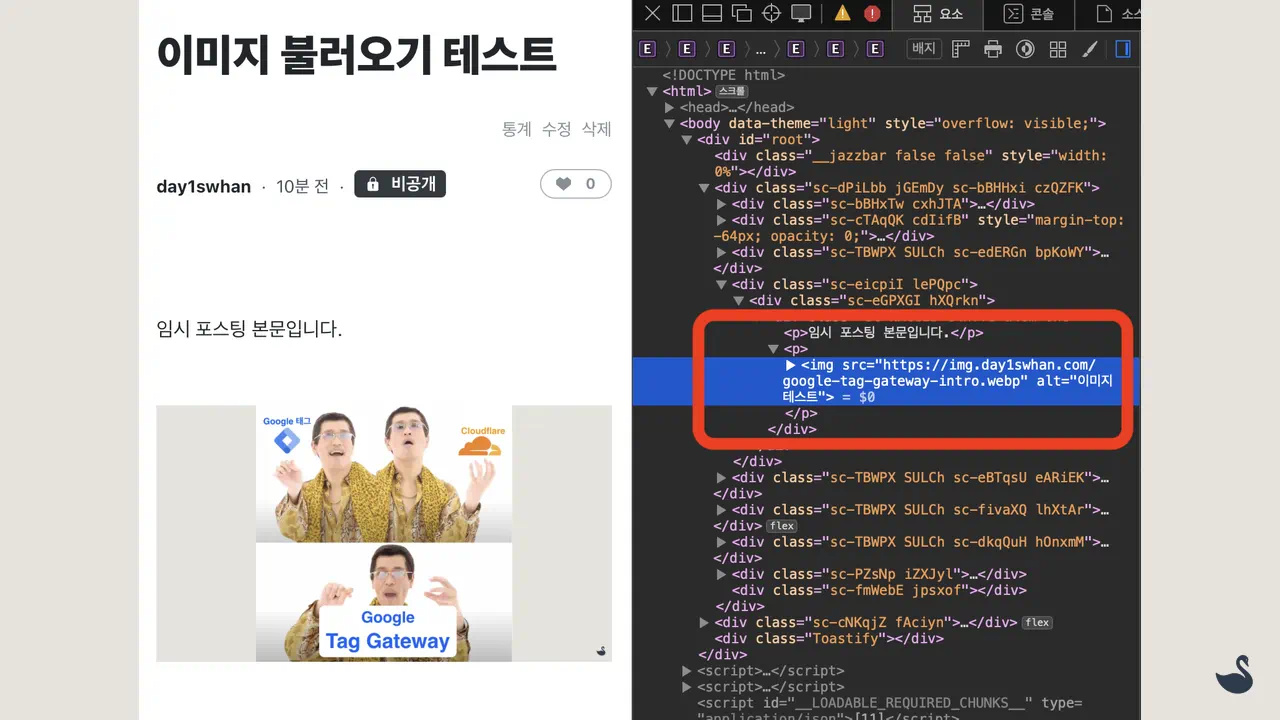
Markdown 문법으로 CDN에 업로드된 이미지를 삽입, 네트워크 호출을 확인해 보면 다행히 이미지가 Velog 소유 도메인으로 강제 캐싱 되지 않는 것을 보실 수 있습니다.
<!-- 이미지 테스트용 velog 작성글(md) -->
임시 포스팅 본문입니다.

작동 방식
이미지 파일을 사용자 소유 도메인에서 제공할 수 있는 것을 확인했으니 이미지에 식별 값(slug)을 부여 후 CDN이 아닌, 프로그래밍 가능한 인프라를 이용해 응답을 제공, 식별 값을 KV의 Key prefix로 사용해서 호출 기록을 저장하면, 간단하게 페이지 뷰를 구할 수 있게 됩니다.
저는 컴퓨팅, 스토리지 인프라로 각각 Cloudflare Workers, Workers KV를 사용했는데요, 이유는 다음과 같습니다.
- Cloudflare Workers: 이미지(1x1 픽셀) 호출 정보를 가공해서 저장소로 보내는 컨트롤러
- 하루 100,000개의 호출 무료 제공.
- 제 게시글이 하루 100,000 페이지 뷰 이상 나올 일은 절대 없음
- Workers KV: 단순하며 빠르게 작동하는 KEY-VALUE 구조의 저장소.
- 하루 100,000개의 GET 작업 무료
- 하루 1,000개의 PUT, LIST 작업 무료
- PUT: 하루 1,000개의 방문자 카운팅 정보를 저장 가능
- LIST: 응답 캐싱을 이용하면 하루 1,000개 이상의 페이지 뷰 정보를 제공 가능
- 99% Velog 유저들의 게시글에는 하루 1,000명 이상의 방문자가 나오지 않음

데이터 구조
정렬을 지원하는 KEY-VALUE 구조에 맞게 데이터 구조를 설계했는데요, 최소한의 중복 방문자 처리를 위해 날짜, ip, userAgent, 이미지 식별 값(slug)을 HASH 함수를 이용해 SESSION_ID 값으로 만들어주고, 이미지 호출 요청이 들어오면 아래처럼 하나씩 쌓아나가면 됩니다.
참고) SessionId는 일 단위로 갱신됩니다.
- SESSION_ID: SHA-256 기반 해시
- KEY:
view:${SLUG}:${SESSION_ID} - VALUE: User Agent 정보, Date
const sid = await getSessionId({ ip, userAgent, postId });
const key = `view:${postId}:${sid}`;
const value = { sid, userAgent, date: getDateISO() };
API Endpoints
현재까지 구현된 Endpoint 정보들 확인하고 하나씩 알아보겠습니다.
GET /view.png?id={postId} # 트래킹 픽셀(수집)
GET /posts/{postId}/views # 조회수 확인(캐시)
GET /posts/{postId}/sessions # 세션 ID 목록(캐시)
GET /posts/{postId}/sessions/{sessionId} # 세션 상세정보 확인
페이지 뷰 업데이트
GET /view.png?id={postId}
페이지 뷰 업데이트를 위해 사용할 Endpoint는 최대한 단순하게 작동할 수 있도록 id 값만 사용했습니다. 어차피 헤더 값에 어디서 이미지 호출했는지를 보여주는 Referer 정보가 있으니 굳이 URL 복잡하게 만들 이유가 없습니다.
Workers는 다음과 같이 QueryString으로 넘어온 postId(slug), 요청 헤더에서 가져온 UserAgent 정보를 이용해 SessionId를 생성한 후 단순 PUT 명령만을 이용해 페이지 뷰 정보를 업데이트할 수 있습니다.
// index.ts
...
app.get("/view.png", async (req, context) => {
const { ctx, env, query } = context;
const { id: postId } = query;
...
const sid = await getSessionId({ ip, userAgent, postId });
const key = `view:${postId}:${sid}`;
const value: PageView = { sid, userAgent, date: getDateISO() };
// 비동기 처리 > 사용자 즉시 응답 가능
ctx.waitUntil(env.WORKERS_KV.put(key, JSON.stringify(value)));
return new Response(pngBody, {
headers: {
"Content-Type": "image/png",
"Cache-Control": "no-store, no-cache, must-revalidate, max-age=0",
Pragma: "no-cache",
Expires: "0",
},
});
});
저는 SessionId를 구하기 위해 Hash 함수(SHA-256)를 이용했는데요, base64url로 인코딩된 해시 값을 그대로 사용하면 너무 길어져서 보기 힘드니 적당히 충돌 나지 않는 범위인 128비트로 잘라낸 후 인코딩하면 사람이 납득 가능한 길이인 22자로 줄일 수 있습니다.
// constants.ts
const getSessionId = async (input: { ip: string; userAgent: string; postId: string }) => {
const { ip, userAgent, postId } = input;
const [date, _] = new Date().toISOString().split("T");
const key = [date, ip, userAgent, postId].join("|");
const buffer = new TextEncoder().encode(key);
const hashBuffer = await crypto.subtle.digest("SHA-256", buffer);
const shortBytes = new Uint8Array(hashBuffer).slice(0, 16); // 128 bit
const shortBase64 = btoa(String.fromCharCode(...shortBytes))
.replace(/\+/g, "-")
.replace(/\//g, "_")
.replace(/=+$/, "");
return shortBase64;
};
이제 트래킹 픽셀을 Markdown 문법으로 삽입하고 방문자가 페이지 로드하면
<!-- 1x1 pixel 등록 -->

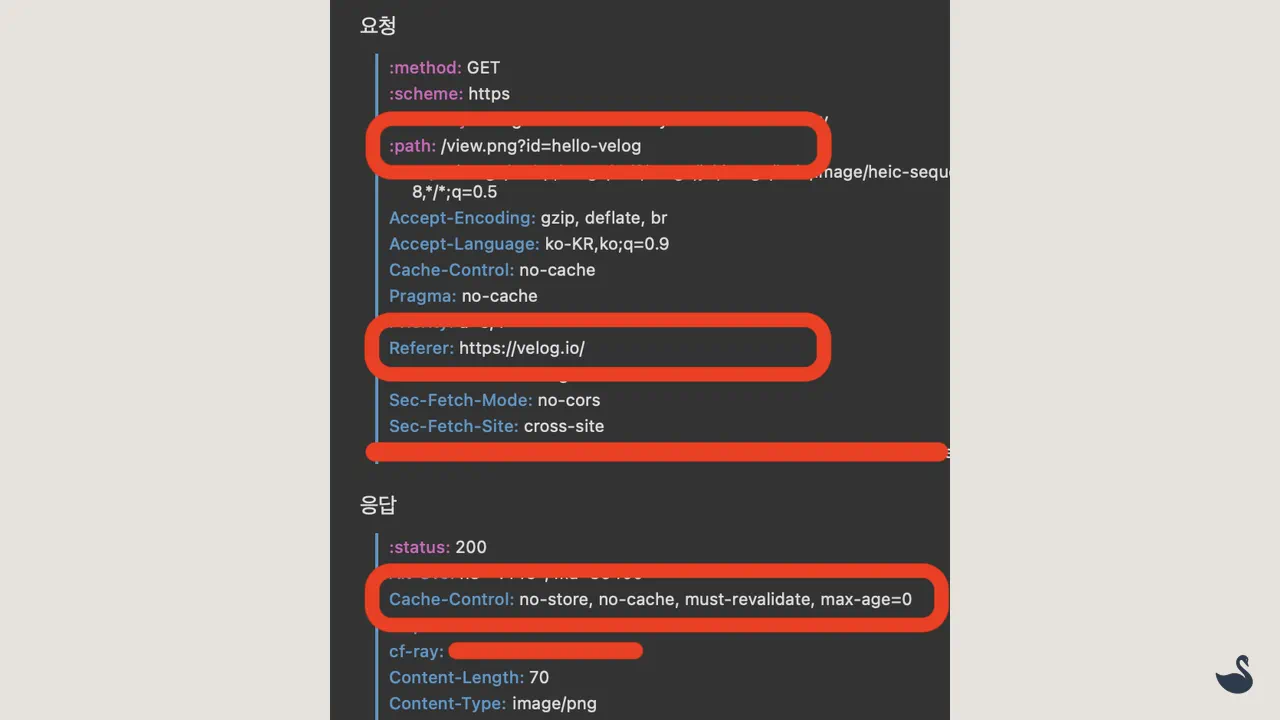
호출된 이미지에 브라우저 캐시 정책(no-cache) 잘 적용되었고, 세션 정보(페이지 뷰 정보)도 업데이트된 것을 보실 수 있습니다.
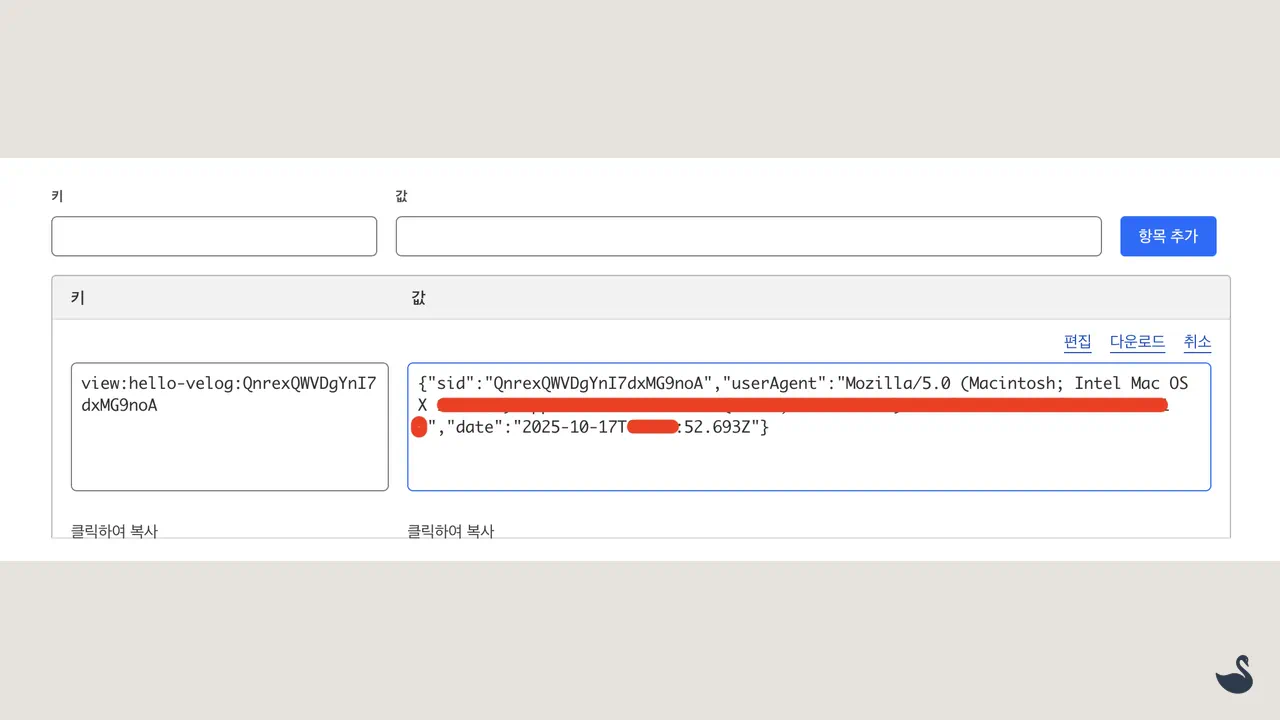
페이지 뷰 조회
GET /posts/{postId}/views
조회 API 경우에는 추후 확장성(검색, 정렬)을 고려해 REST 하게 설계해 줘야 합니다.
조회 요청이 들어오면 LIST 명령으로 세션 정보를 가져온 후 이를 단순 카운팅 하면 총 조회수를 구할 수 있는데요, 각 포스팅에 맞는 세션 정보만 깔끔하게 가져오기 위해서는 위에서 설계한 데이터 구조(view:${SLUG}:${SESSION_ID})에 맞춰 prefix(view:${SLUG}:)를 이용하면 됩니다.
// index.ts
...
app.get("/posts/:postId/views", async (req, context) => {
const { ctx, env, params, query } = context;
const { postId } = params;
const { cursor } = query;
const prefix = `view:${postId}:`;
const listKeys = await env.WORKERS_KV.list({
prefix,
...(cursor && { cursor }),
});
const { list_complete, keys } = listKeys;
const response: PageViewInfo = {
id: postId,
pageCount: keys.length,
page: {
has_more: !list_complete,
next_cursor: "cursor" in listKeys ? listKeys.cursor : undefined,
},
lastUpdate: getDateISO(),
};
return Response.json(response, {
status: 200,
headers: {
"x-cache": "MISS",
"Cache-Control": "public, max-age=300, stale-while-revalidate=300",
},
});
});
캐싱 적용
Workers KV 경우에는 LIST 요청을 하루 1,000개로 제한하고 있으니 응답을 통째로 캐싱해서 크게 중요하지 않은 실시간성을 어느 정도 희생하면 하루 1,000개 이상의 페이지 뷰 요청을 처리할 수 있습니다.
Workers Runtime에서 기본적으로 지원하는 waitUntil 함수를 이용하면 비동기로 캐시 업데이트가 가능하고, expirationTtl 옵션으로 캐시 자동 만료 시켜서 저희가 저장소에 직접 DELETE 요청하지 않아도 내부적으로 알아서 삭제 처리할 수 있도록 만들어 줍니다.
// index.ts
app.get("/posts/:postId/views", async (req, context) => {
...
// cacheTtl을 이용한 엣지 네트워크 캐싱(5분간 중앙 저장소 접근 안해도 됨)
const cacheKey = cursor ? `views:cache:${postId}:${cursor}` : `views:cache:${postId}`;
const cacheValue = await env.WORKERS_KV.get<PageViewInfo>(cacheKey, { type: "json", cacheTtl: 300 });
if (cacheValue) {
return Response.json(cacheValue, {
status: 200,
headers: {
"x-cache": "HIT",
"Cache-Control": "public, max-age=300, stale-while-revalidate=300",
},
});
}
const prefix = `view:${postId}:`;
...
const response: PageViewInfo = {...};
// 사용자 즉시 응답을 위한 비동기 캐시 업데이트(5분 후 자동 삭제)
ctx.waitUntil(env.WORKERS_KV.put(cacheKey, JSON.stringify(response), { expirationTtl: 300 }));
return Response.json(response, { ... });
});
페이지 세션 조회
현재 데이터 구조에서는 각 KEY마다(view:${SLUG}:${SESSION_ID}) 세션 정보(SessionId, UserAgent, Date)를 담고 있어서 포스팅별 세션 상세정보를 한 번에 보여주려면 동시에 너무 많은 GET 요청이 발생하는 문제가 있습니다.
그래서 아쉽게도 포스팅별 세션 목록 조회, 세션 상세정보 조회 이렇게 두 개의 API로 나눠서 구현했는데요, 사실 세션 목록 조회는 위에서 페이지 뷰 조회 시 사용한 방법과 99.9% 동일합니다.
세션 목록 조회
GET /posts/{postId}/sessions
페이지 뷰 조회와의 차이점은 가져온 세션 목록을 카운팅 해서 제공하는지, 아니면 그대로 제공하는지 인데요. 여기에 작은 추가 작업은 가져온 KEY 값인 view:${SLUG}:${SESSION_ID} 문자열에서 SessionId만 깔끔하게 분리해서 제공하는 것입니다.
이것도 페이지 뷰 조회와 마찬가지로 응답을 통째로 캐싱 적용이 가능하니 cacheTtl, expirationTtl 모두 5분간 적용해 주도록 하겠습니다.
// index.ts
app.get("/posts/:postId/sessions", async (req, context) => {
...
const cacheKey = cursor ? `sessions:cache:${postId}:${cursor}` : `sessions:cache:${postId}`;
const cacheValue = await env.WORKERS_KV.get<SessionInfo>(cacheKey, { type: "json", cacheTtl: 300 });
if (cacheValue) {
return Response.json(cacheValue, { ... });
}
// KEY 값에서 SESSION_ID 정보만 분리
const sessionIds: SessionId[] = keys.map((d) => {
const [event, postId, sid] = d.name.split(":");
return { sid };
});
// PageViewInfo에서 sessionIds 정보만 추가됨
const response: SessionInfo = {
...
data: sessionIds,
};
ctx.waitUntil(env.WORKERS_KV.put(cacheKey, JSON.stringify(response), { expirationTtl: 300 }));
return Response.json(response, { ... });
});
추가 1) cacheTtl: 사용자 요청을 처리하는 네트워크 엣지 단에서 캐싱 해놓고, 다음 요청 시 중앙 저장소에 접근할 필요가 없게 도와줍니다. 응답 속도 개선 효과가 있습니다.
추가 2) expirationTtl: KV 저장소에서 마지막 수정 시간 이후 몇 초 후에 자동 삭제할지 설정하는 옵션. 만약 정확한 시간을 지정하고 싶으면 UTC 기준으로 expiration 옵션을 이용하시면 됩니다.
세션 상세정보 조회
GET /posts/{postId}/sessions/{sessionId}
이제 세션 목록 조회를 통해서 가져온 SessionId 값으로 각 포스팅 방문자의 UserAgent, 방문 시간을 가져올 수 있습니다.
app.get("/posts/:postId/sessions/:sessionId", async (req, context) => {
const { env, params } = context;
const { postId, sessionId } = params;
// base64url(128-bit) → 항상 22자
if (sessionId.length !== 22) {
return Response.json({ message: "Bad Request, please check sessionId" }, { status: 400 });
}
const key = `view:${postId}:${sessionId}`;
const data = await env.WORKERS_KV.get<PageView>(key, { type: "json", cacheTtl: 300 });
if (!data) {
return Response.json({ message: "Not Found" }, { status: 404 });
}
return Response.json(data, {
status: 200,
headers: {
"x-cache": "MISS",
"Cache-Control": "public, max-age=300, stale-while-revalidate=300",
},
});
});
한계
아무래도 빠른 개발을 위해 단순한 저장소인 KV를 사용하다 보니 다음과 같은 한계가 있습니다.
- Eventual consistency: Workers KV PUT 요청은 보통 즉시 반영되지만 캐시된 데이터 버전에 따라 최대 60초 또는 그 이상이 걸릴 수도 있습니다. 실시간성 보장이 필요하면 Durable Objects(DO) 사용을 고려해야 합니다.
- LIST 의존: LIST 명령을 이용한 카운팅 방식은 (페이지 뷰가 꾸준히 나온다는 가정하에) 시간이 지나면서 가져와야 하는 KEY 값들이 많아질수록 느려짐. Cron 작업으로 꾸준히 저장 구조를 업데이트하거나, DO 또는 Analytics Engine 사용을 고려해야 합니다.
지원 예정
확장성에 집착하는 개발자답게 최대한 빠른 시일 내에 다음과 같은 기능들을 추가할 예정입니다.
- 날짜별 정렬: 서버리스 블로그 댓글 API 30분 만에 만들어보기에서 최신 댓글 정렬을 위해 사용한 방식인 Unix Time을 이용하면 최신 세션 기준으로 정렬된 목록을 제공할 수 있습니다.
- Rate Limit: 인기 Velog 유저라면 시기와 질투에 눈이 먼 사용자들이 악의적 요청을 날릴 수 있으니 대비책이 필요합니다. 아마 전 해당되지 않아서 천천히 추가될 예정입니다.
- 검색: API 추가로 지원 예정.
- 날짜: 특정 날짜, 기간별 검색 기능. KEY 구조 변경 필요
- 세션: 특정 세션 활동 정보 검색 기능. 현재 세션 정보는 각 포스팅에 대해서 하루 동안 유효함. 개인정보보호 정책 검토 필요
- 브라우저/OS: UserAgent에서 파싱 한 정보로 제공 예정. 정교하진 않아도 대략적인 파악 가능
- 서비스 API: 누구나 쉽게 이메일 인증 + 개인키 발급으로 사용할 수 있도록 API를 서비스 형태로 제공 예정
- 웹훅: 페이지 뷰 이벤트 발생 시 POST 요청 제공. 개발자들이 좋아하는 Slack을 이용한 알림 가능
- 이메일: 웹훅 처리가 귀찮은 사용자들을 위해 고전이지만 편리한 알림 기능
- custom campaign: 설정된 이벤트(ex. 특정 조회수 도달)가 통합된 이미지 식별 값(slug) 제공
더보기
추천 컨텐츠
- #블로그 만들기 시리즈 #Cloudflare #마이크로서비스
Next.js SSG 블로그에 서버리스 댓글 API 연동하기
SSG(Static Site Generation) 방식으로 빌드 된 Next.js 블로그에 Cloudflare Workers 기반 댓글 API를 연동하는 과정을 소개합니다.
- #블로그 만들기 시리즈 #Cloudflare #마이크로서비스
서버리스 블로그 댓글 API 구축하기: Workers KV로 30분 만에 만들어보자
Workers KV를 이용한 서버리스 블로그 댓글 API 개발기를 공유합니다.
- #블로그 만들기 시리즈 #Cloudflare #마이크로서비스
Cloudflare Workers & KV 이용해서 서버리스 방문자 카운팅 API 만들기 (2/2)
쿠키 기반 중복 방문자 처리, 커스텀 도메인, CORS, 응답 캐싱 기능이 적용된 방문자 카운팅 API를 블로그에 적용하는 방법을 설명합니다.
댓글