Cloudflare Workers & KV 이용해서 서버리스 방문자 카운팅 API 만들기 (1/2)

Cloudflare Workers, Workers KV를 이용해서 간단한 서버리스 방문자 카운팅 API 만드는 방법을 알아보겠습니다.
들어가며
가상화, 마이크로서비스가 점점 각광받고, 마이크로서비스를 더욱 효율적으로 운영하기 위한 서버리스 컴퓨팅이 발전하는 시대입니다.
블로그에 얼마나 많은 방문자들이 찾아오는지, 블로그 인기 포스팅들이 무엇인지 정도는 알고 있어야 개발 블로그를 운영하는 사람이라고 할 수 있지 않을까요?
서버리스, API, 마이크로서비스 같이 클라우드 시대에 Fancy한 키워드 모두 충족시킬 수 있는 개발 블로그의 도파민 프로젝트! 서버리스 방문자 카운팅 API 만드는 방법을 알아보겠습니다.
도구 소개
Cloudflare Workers
Workers 홈페이지 들어가 보면 이런저런 설명 있지만, 본질은 결국 AWS Lambda 같은 FaaS(Function as a Service) 방식의 서버리스 컴퓨팅이라고 보시면 됩니다.
개발자 세계에서 잘나가는 AWS Lambda를 이용해도 되지만, 저는 개인적으로 간단한 API 개발에 Lambda를 사용하기에는
- IAM, API Gateway, 도메인 연결 귀찮음
- 간단한 key-value 방식에서 굳이 Node.js API, 외부 모듈을 사용할 일 없음
- 뭔가 딱딱한 기업용 API 냄새남
이 세 가지 이유로 새로운 경험도 해보고, 저희가 배포한 코드가 Cloudflare의 CDN을 타고 지구 전체에 배포되는 짜릿한 경험도 해보며 도파민도 충족할 수 있는 Workers를 사용해 보겠습니다.
개발 블로그에 가장 중요하다고 볼 수 있는 비용을 먼저 살펴보면
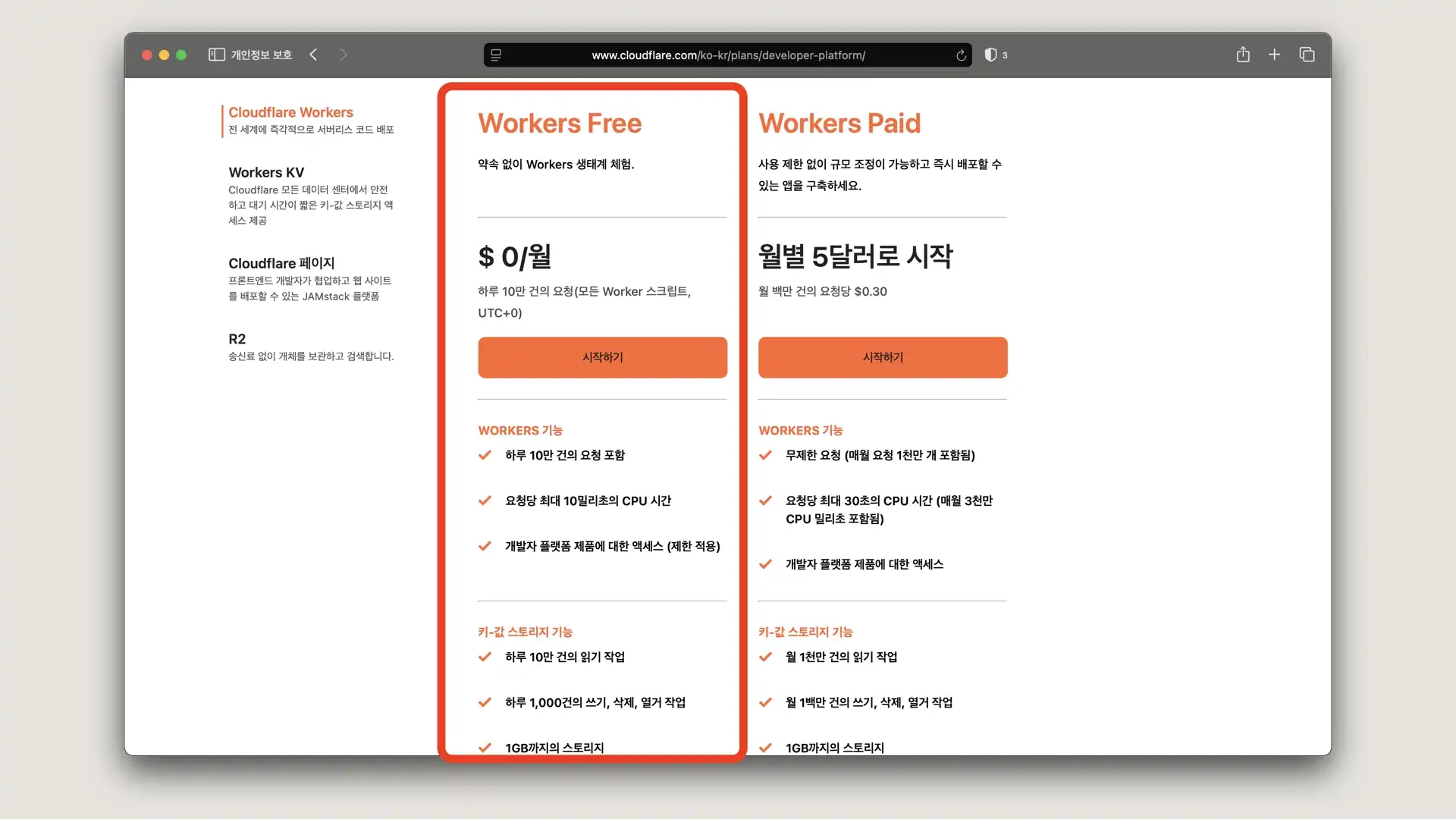
하루 10만 request, 요청당 10밀리 초의 cpu time? workers에서 외부 api 요청같이 sub-request 대기 시간에 대해서는 cpu time에 포함시키지 않는다고 하는데, 이 정도면 블로그용으로는 차고 넘치게 충분합니다. (If a Worker's request makes a sub-request and waits for that request to come back before doing additional work, this time spent waiting is not counted towards CPU time.)

저희 블로그 방문자 수가 허접하다고 블로그 시스템 자체도 허접하면 안 되겠죠. Cloudflare 제품 설명 페이지 보시면 Node.js에서 JavaScript 실행을 위해 사용하는 Chrome V8 engine을 이용해서 작동한다고 하는데요, 저희가 얻어 갈 수 있는 장점은
- 샌드박싱: 프로세스 단위로 샌드박스 환경을 제공해서 다른 사람의 코드가 저희 코드 실행 환경에 영향을 미치지 않도록 보장됩니다.
- 콜드 스타트 없음: V8에서 직접 실행되어서 Lambda가 사용하는 경량 가상머신(Firecracker)보다 더 가볍게 작동합니다.
이렇게 API 요청에 더 빠르고 안전하게 응답할 수 있고, Cloudflare는 같은 서버에 더 많은 사람들 밀어 넣어서 비용을 절감할 수 있는 win-win 구조입니다.
Cloudflare Workers KV
뒤에 KV가 붙은 거에서 알 수 있듯이, Workers에서 사용할 수 있는 Key-Value 스토리지입니다. 이 친구의 장점은
- 외부 모듈 가져올 필요 없음
- workers 설정 파일(wrangler.jsonc)에 단순 변수 등록만 하면 바로 사용 가능
이렇게 심플하다는 건데요, 저희같이 postId를 key 값으로 단순 조회수 카운팅 하는 api에 딱 알맞은 것 같습니다.
물론 클라우드플레어 측에서는 Caching API responses, Storing user configurations / preferences 같이 한번 쓰고, 자주 읽는 데이터에 사용할 것을 권장하지만 저희 블로그같이 작고 소중한 트래픽 처리하기에는 충분합니다. (언젠가 하루 방문자 1,000명 넘어가서 Redis, Kafka를 이용하는 날이 오기를 꿈꿔봅니다)
Workers 프로젝트 생성
Cloudflare에서 create-cloudflare라는 CLI 툴을 제공하긴 하지만, 저희는 최대한 가볍게 시작할 수 있도록 직접 프로젝트 구조 잡고 시작하겠습니다.
동영상도 Shorts 같이 3분 이내 영상만 보는 시대에 맞춰 버튼 딸깍 하나로 시작하실 수 있도록 샘플 프로젝트 미리 만들어놨으니 clone 해주시면 됩니다.
git clone https://github.com/day1swhan/visitor-counter-example.git && \
cd visitor-counter-example && \
git checkout -b dev 109d4b4f && \
npm install && \
npm run types
index.ts 파일 보시면
// src/index.ts
export default {
async fetch(request, env, ctx): Promise<Response> {
...
return new Response("Hello visitor-counter-example!");
},
} satisfies ExportedHandler<Env>;
Lambda 함수 사용할 때 handler 함수를 export 하듯이, Workers 함수로 요청 핸들링하기 위해서는 fetch 함수를 export 해주시면 됩니다.
개발 모드
일단 로그 찍어보면서 fetch 함수가 어떻게 작동하는지 알아보겠습니다.
저희 목표는 /view?id=my-post-slug 방식으로 api를 호출하면, 쿼리스트링으로 전달받은 postId 값을 key로 사용해서
- GET: 기존 postId에 저장된 카운팅 정보 가져오기
- ADD: 기존 카운팅 정보에 +1
- PUT: postId에 카운팅 정보 덮어쓰기
이렇게 단순 GET, PUT 요청만으로 작동하게 만들어보겠습니다.
// wrangler.jsonc
{
"name": "visitor-counter-example",
...
"kv_namespaces": [
{
"binding": "VISITOR_COUNT_DB",
"preview_id": "1234567890abcdef1234567890abcdef" // 이건 로컬용, 아무 의미 없음
}
]
}
먼저 fetch 함수에서 변수만으로 저장소 접근할 수 있도록 wrangler.jsonc 파일을 수정해 주셔야 하는데요, kv_namespaces 부분에 KV 스토어 접근할 때 사용할 변수인 VISITOR_COUNT_DB 넣어주시고, preview_id(로컬에서만 작동) 값에는 아무거나 넣어줍니다.
쓸데없는 요청들이 DB 접근하지 않도록 기본적인 라우팅 정보 구분해서 응답할 수 있게 index.ts 파일 수정하고
// src/index.ts
import { notFound, badRequest } from "./api/response";
import { middlewareResolveRequest } from "./middleware/middleware-resolve-request";
export default {
async fetch(request, env, ctx): Promise<Response> {
// request 정보 다루기 쉽게 포맷 변환해주기
const { method, path, query } = await middlewareResolveRequest(request);
const routeKey = method + " " + path;
switch (routeKey) {
case "GET /view": {
const postId = query["id"];
if (!postId) {
return badRequest();
}
// view 이벤트에 사용할 key
const key = `view:${postId}`;
// 기존 카운팅 정보 가져오기
const before = await env.VISITOR_COUNT_DB.get(key);
// 요청 들어왔으니 +1 해주고
const count = Number(before || 0) + 1;
// 언제 업데이트 된건지 응답 정보에 넘겨주기 (선택)
const lastUpdate = new Date().toISOString().replace(/\.\d{3}Z$/, "Z");
// 최신 카운팅 정보로 덮어쓰기
await env.VISITOR_COUNT_DB.put(key, String(count));
return Response.json({ postId, count, lastUpdate });
}
default: {
return notFound();
}
}
},
} satisfies ExportedHandler<Env>;
개발 모드로 실행해서
npm run dev
Your Worker has access to the following bindings:
Binding Resource Mode
env.VISITOR_COUNT_DB (1234567890abcdef1234567890abcdef) KV Namespace local
⎔ Starting local server...
[wrangler:info] Ready on http://localhost:8787
curl 이용해서 api 응답 확인해보시면
curl 'http://localhost:8787/view?id=my-first-post'
{
"postId": "my-first-post",
"count": 1,
"lastUpdate": "2025-07-14T09:10:36Z"
}
정상적으로 응답 주는 걸 볼 수 있습니다.
배포 준비
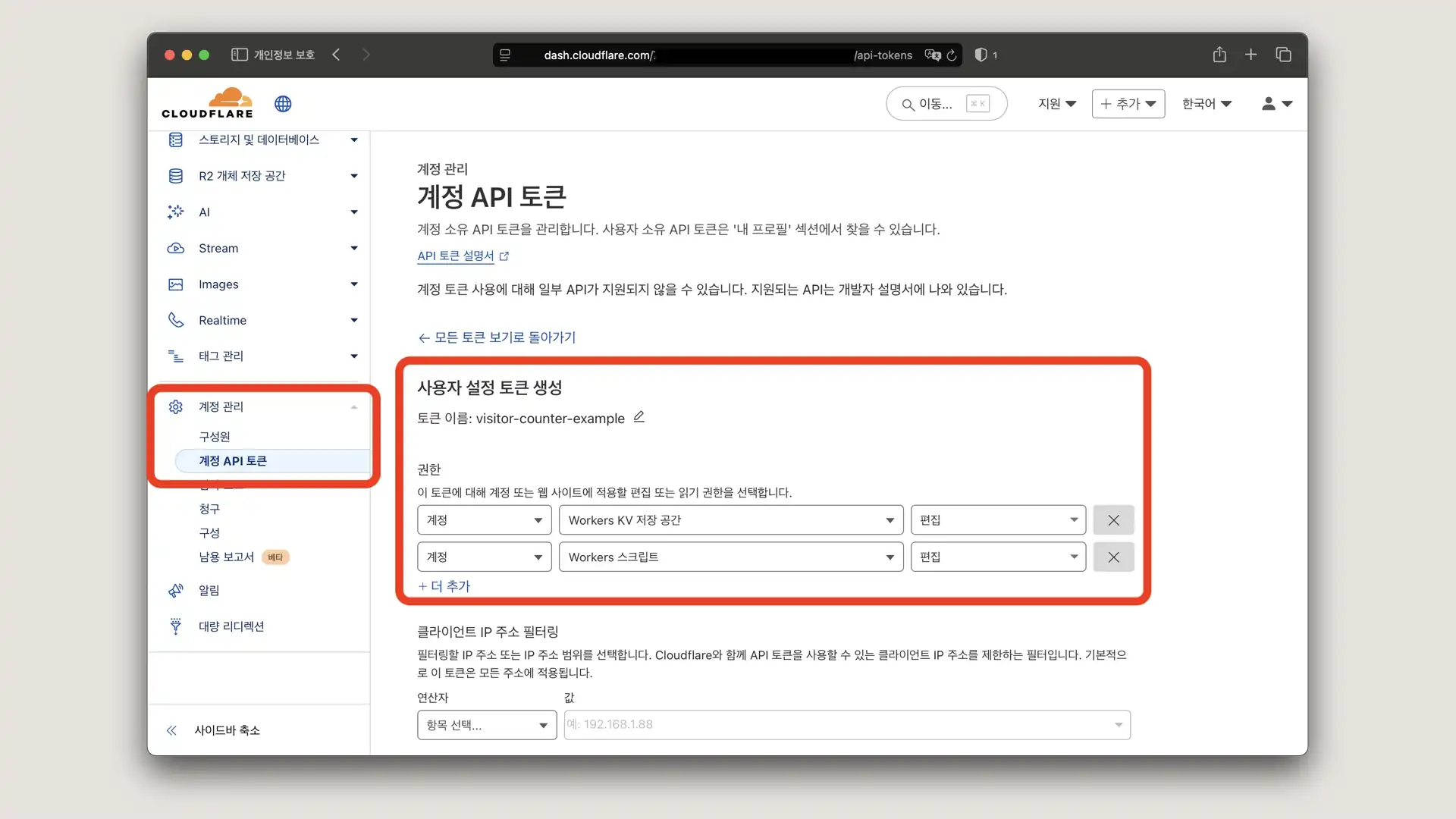
계정 API 토큰 발급
wrangler를 이용한 cli 환경에서 배포하기 위해서는 API 토큰 발급 후 환경변수에 등록해 줘야 합니다.
cloudflare dashboard에서 계정 관리 - 계정 API 토큰 - 사용자 설정 토큰 생성
계정 단위에서 편집 권한을
- Workers KV 저장 공간
- Workers 스크립트
이렇게 두개 넣어주시면 됩니다.
# /sh
export CLOUDFLARE_API_TOKEN="xxxxxxxxxx"
KV Namespace 생성
아쉽게도 Worker가 배포될 때 Key-Value 스토어를 자동으로 생성해 주지 않으니, 직접 wrangler 이용해서 생성해 주셔야 하는데요
npx wrangler kv namespace create VISITOR_COUNT_DB
Resource location: remote
🌀 Creating namespace with title "VISITOR_COUNT_DB"
...
✨ Success!
Add the following to your configuration file in your kv_namespaces array:
{
"kv_namespaces": [
{
"binding": "VISITOR_COUNT_DB",
"id": "987654321abcdefg" // 프로덕션용
}
]
}
KV Namespace 적용
workers가 배포 후 kv 저장소에 접근할 수 있도록 wrangler.jsonc 파일에 방금 생성된 id 값을 반영해 줍니다.
// wrangler.jsonc
{
"name": "visitor-counter-example",
...
"kv_namespaces": [
{
"binding": "VISITOR_COUNT_DB",
"id": "987654321abcdefg", // 프로덕션용, 배포시 포함되어야됨
"preview_id": "1234567890abcdef1234567890abcdef" // 이건 로컬용, 아무 의미 없음
}
]
}
배포
이제 모든 준비가 끝났으니 workers를 배포해 보겠습니다.
npm run deploy
Total Upload: 2.93 KiB / gzip: 1.09 KiB
Your Worker has access to the following bindings:
Binding Resource
env.VISITOR_COUNT_DB (xxxxxx) KV Namespace
...
Deployed visitor-counter-example triggers (0.41 sec)
https://visitor-counter-example.day1swhan.workers.dev
배포가 성공하면 workers.dev 도메인 아래에 서브도메인으로 접속 가능한 링크를 발급해 줍니다. curl 명령어를 이용해 정상 작동하는지 확인해 보시면
curl 'https://visitor-counter-example.day1swhan.workers.dev/view?id=my-first-post'
{
"postId": "my-first-post",
"count": 1,
"lastUpdate": "2025-07-14T09:20:36Z"
}
로컬 개발 환경과 동일하게, 하지만 전 세계에 배포된 상태로 잘 작동하는 것을 보실 수 있습니다.
추가 팁
npx wrangler --help옵션으로 더 자세한 wrangler 사용법들을 볼 수 있습니다- worker 삭제하실 때 worker와 연결된 KV 스토어는 자동으로 삭제되지 않으니 직접 삭제해주셔야 합니다.
저희는 프로젝트에 필요한 명령어들만 빠르게 알아보겠습니다.
Worker 삭제
npx wrangler delete
Workers KV 목록
npx wrangler kv namespace list
[
...
{
"id": "abcdefg98765",
"title": "VISITOR_COUNT_DB",
"supports_url_encoding": true,
"beta": false
}
]
Workers KV 삭제
npx wrangler kv namespace delete --namepace-id NAMESPACE_ID
마무리
이렇게 일단 작동 가능한 서버리스 방문자 카운팅 API를 만들어 보았습니다. 지금같이 방문자가 별로 없는 환경에선 이 정도면 충분하지만 하루 1000만 사용자가 방문하면 어떻게 시스템 뜯어고칠지 쓸데없이 망상해보며, 다음 포스팅에서는 중복 방문자 처리, 커스텀 도메인, CORS, 응답 캐싱, Component 통합 등 블로그에 본격적으로 API 적용하는 방법을 다뤄보겠습니다.